DWDM \ ClassificationClassification is a action / process of classifying something.
General Approach to Solve a Classification Problem Steps 1. Divide the Input into 2 sets. a. Training Set. b. Test set. 2.Training Set is used to build a classification model. 3. New classification model is used on test set to pedict the class label of each test record. 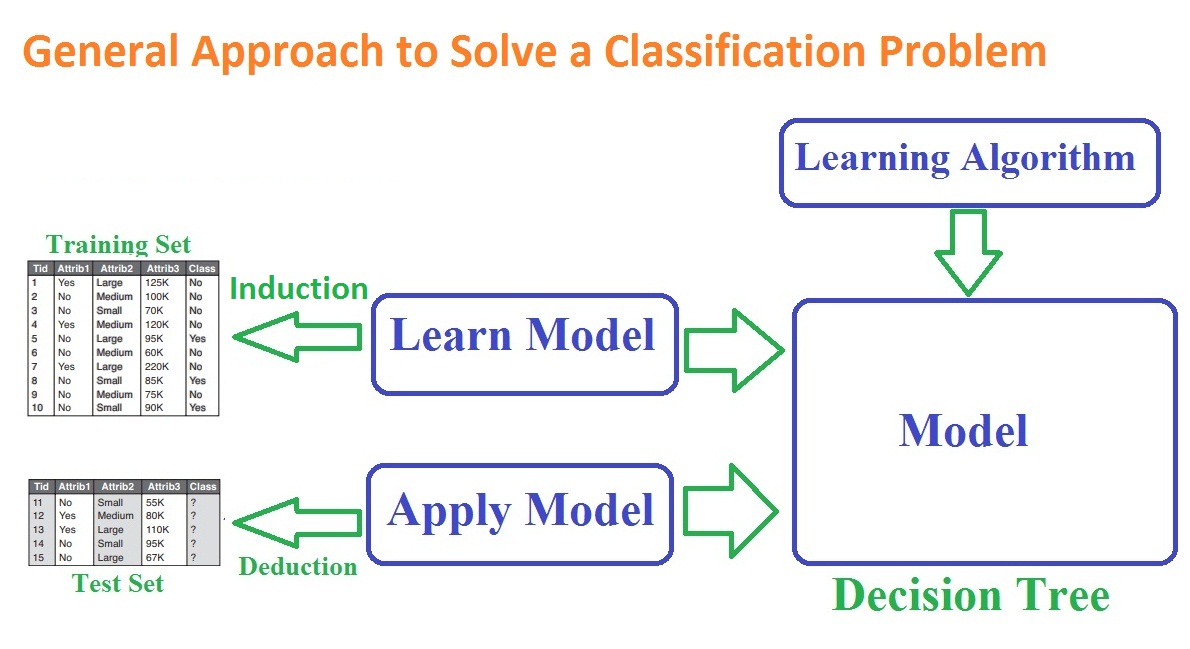
Classification models
Evaluation of Classifiers Classifier algorithm is used to map the input data to a specific category. Classification model used for predicting a new class labels for a given data. "Methods (5)" of Evaluation of Classifiers / Classification Model Evaluation
"Metrics (5)" of Classification Evaluation Every classifier has 2 classes and outputs one of two possible outputs: true or false. Confusion Matrix / contingency Table 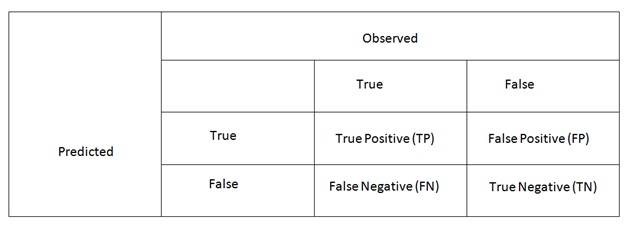 Metric are used for measurement used in evaluating our different classification models. 1. Accuracy =proportion of true results among the total number of cases examined Accuracy = (TP+TN)/(TP+FP+FN+TN) 2. Precision = proportion of predicted Positives is truly Positive= (TP) / (TP+FP) 3. Recall = proportion of actual Positives is correctly classified= (TP) / (TP+FN) 4. F1 Score= is the harmonic mean of precision and recall. 5. Sensitivty (the probabilities from the positive classes are separated from the negative classes)= TPR(True Positive Rate)= Recall = TP/(TP+FN) To evaluate your classifier is to train the svm algorithm is the best method
Classification Techniques
Support Vector Machine (SVM) It is usedto separate / classify the dataset into two classes by using a single straight line. Here all points fall in one side are labelled in first class and remaining labelled in the second class. It is used for Web and Text Mining or regression problems. 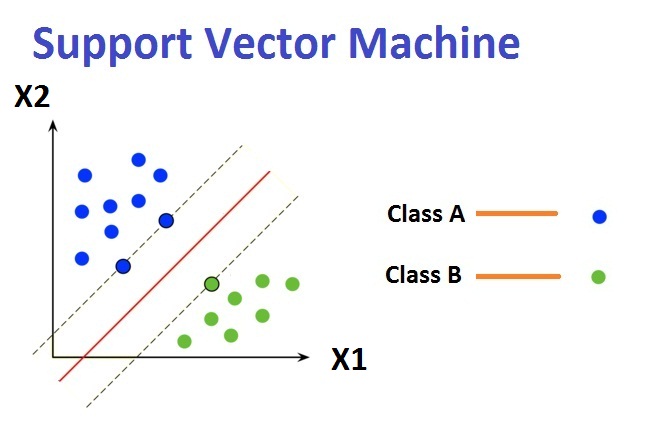 Types of SVM It is of 2 types.They were 1. Linear SVM used for linearly separable data. i.e data set is classified by using a straight line. 2. Non-linear SVM used for Non linearly separable data. i.e data set is cant be classified by using a straight line. Decision Trees It is a tree used as a representation to solve the problem in data mining regarding the decision taking.It contains a root node, branches and leaf nodes.It is used for Web and Text Mining and regression methods.
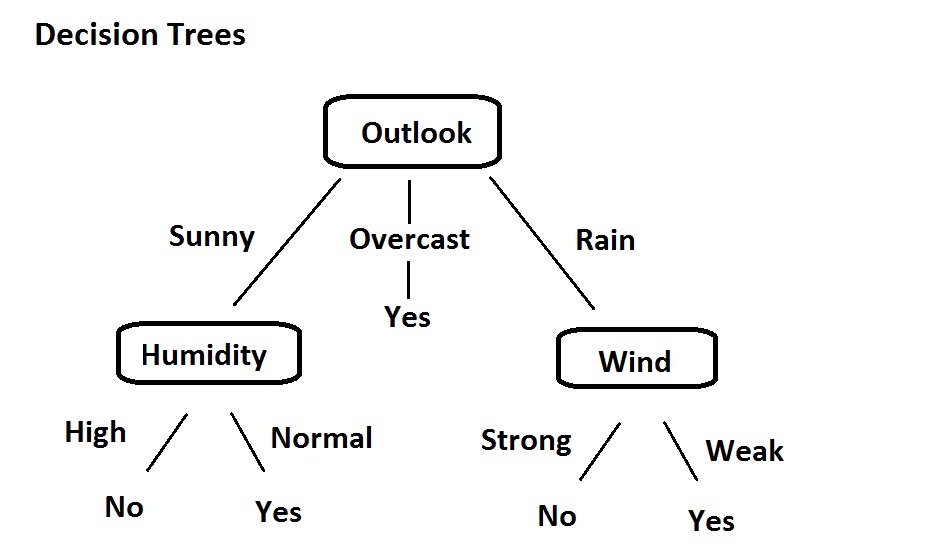 Pruning Pruning is a technique used to reduce the size of decision trees by removing irrelevant sections a of tree. Methods for Expressing attribute test conditions It depends on type of attribute. Types of attributes in a data mining
measures for selecting the best split |
Home Back