Machine learning / Data Sets for Testing and TrainingModelIt is a representation of real world process and is used to predict on the test data. There are 3 data sets used in different stages of the creation of the model. They were
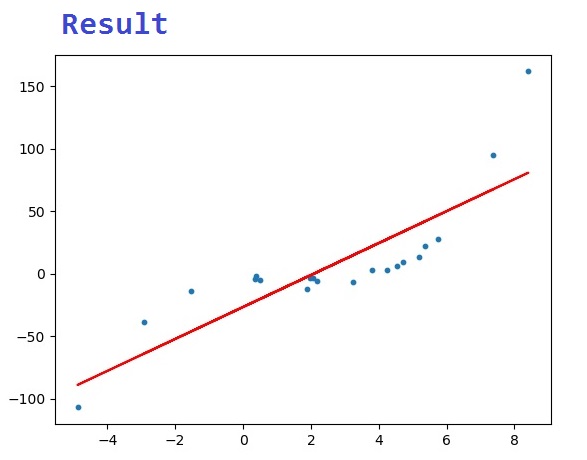
Training dataset It is used to fit the parameters of the model. Validation dataset The validation dataset provides an unbiased evaluation of a model fit on the training dataset while tuning the models hyperparameters.It is used to stop training when the error on the validation dataset increases i.e it’s a sign of over fitting to the training dataset. Test / holdout dataset It is used to provide an unbiased evaluation of a final model fit on the training dataset. Split Into Train or Test Data Set Intial data set = Train Data Set + Test Data Set. Example Train Data Set = 70 % + Test Data Set = 30 % = Initial Data set ( Total Data Set) Apply a linear regression model to this dataset
|